Like many people I quite enjoy playing Wordle, and I quite enjoy playing Worldle, too. I like both of these games so much that I've made completing them my Start Of Day (SOD) procedure.
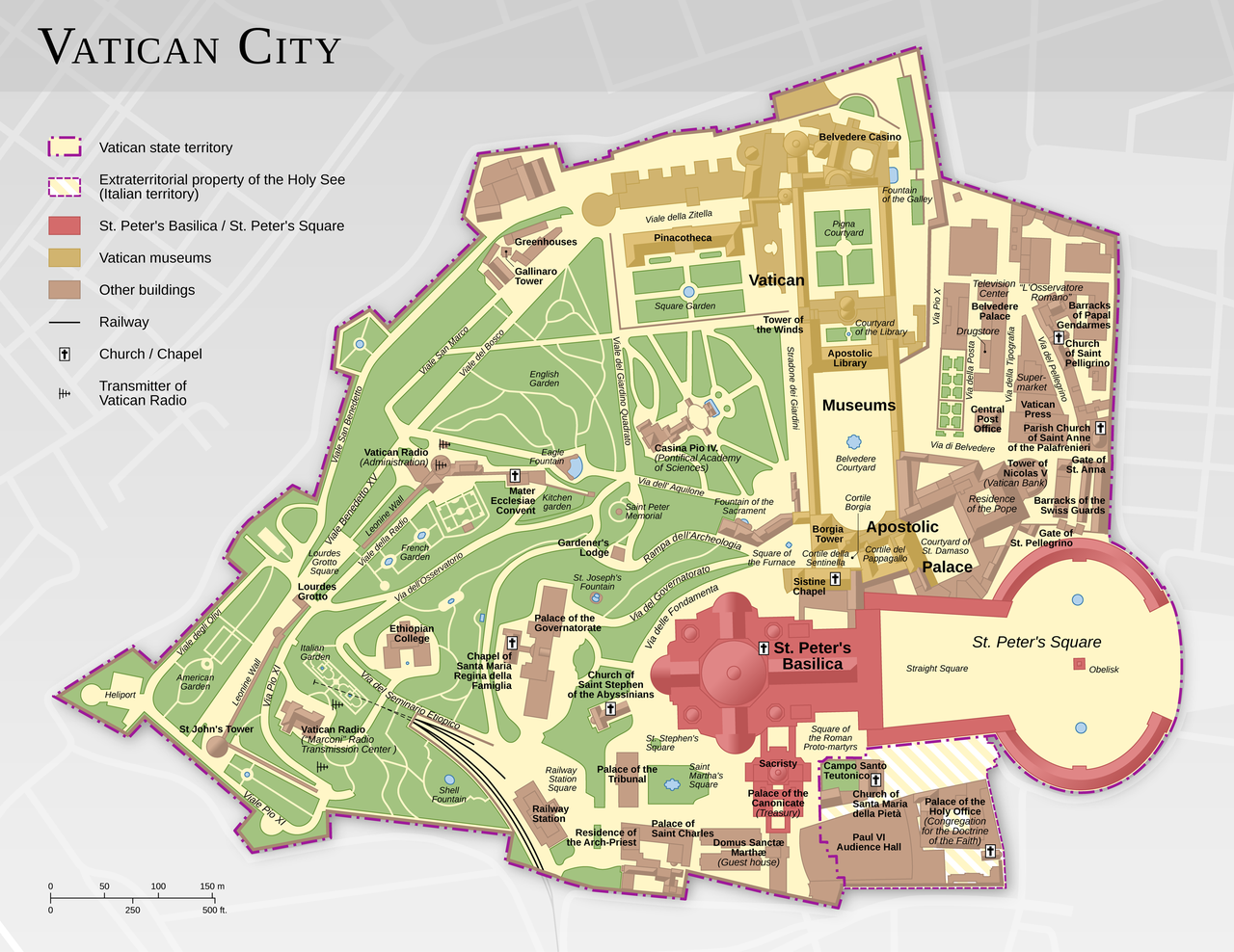
Yesterday's Worldle was Vatican City, a place that J and I visited when we had an amazing five week long trip to Europe in 2005. Worldle gives you a black-on-white image of the geographic area to guess, and each day's image is approximately the same size in your window.
I thought this was pretty easy to guess - to me it just looks like a fortified place like a castle or ... a city state. There aren't too many of those on this planet so it was a 1 from 1 situation. I forgot to save a copy of the clue version, so imagine this picture below but with everything inside the walls filled in, in black:
This morning I got to thinking - if you've only got the edges of a word (start and end letters), how many unique combinations are there? [Yes, I'm only thinking about the English language].
A quick check of /usr/share/dict/words on my workstation (standard Linux dictionary installed) shows that out of 104334 words there are 7044 with five letters. Clarifying that just a little, if you remove those that are capitalised (proper nouns and acronyms) you're left with 4667 five letter words.
>>> import re >>> words = open("words", "r").readlines() >>> len(words) 104334 >>> fivers = [j.strip() for j in words if len(j) == 6] >>> len(fivers) 7044 >>> fivers[0:20] ["ABC's", "ABM's", 'AFAIK', "AFC's", "AMD's", 'ANSIs', 'ANZUS', "AOL's", 'ASCII', "ASL's", 'ASPCA', "ATM's", "ATP's", 'AWACS', "AWS's", "AZT's",'Aaron', 'Abbas', 'Abdul', "Abe's"] >>> fivers = [] >>> for w in words: ... m = re.match("^[a-z]{5}$", w.strip()) ... if m: ... fivers.append(m.group(0)) ... >>> len(fivers) 4667 >>> fivers[0:20] ['abaci', 'aback', 'abaft', 'abase', 'abash', 'abate', 'abbey', 'abbot', 'abeam', 'abets', 'abhor', 'abide', 'abler', 'abode', 'abort', 'about', 'above', 'abuse', 'abuts', 'abuzz']
That's good enough to look at the initial and final letter combinations. To do that we'll use a set:
>>> enders = [(i[0], i[-1]) for i in fivers] >>> len(enders) 4667 >>> snend = set(enders) >>> len(snend) 411 >>> snend {('a', 'z'), ('t', 's'), ('p', 'x'), ('d', 'f'), ('s', 'i'), ('u', 'e'), ('z', 'i'), ('v', 'a'), ('g', 'a'), ('y', 'h'), ('j', 't'), ('t', 'x'), ('m', 'i'), ('l', 'e'), ('j', 'n'), ('k', 't'), ('q', 'k'), ('o', 'l'), ('h', 'x'), ('l', 'h'), ('u', 'a'), ('k', 'n'), ('b', 'l'), ('d', 'i'), ('y', 'a'), ('v', 'd'), ('g', 'd'), ('v', 'g'), ('k', 'u'), ('o', 't'), ('r', 'y'), ('c', 'r'), ('c', 'l'), ('s', 'p'), ('j', 'i'), ('l', 'a'), ('b', 't'), ('m', 'm'), ('k', 'i'), ('u', 'd'), ('c', 'f'), ('n', 'r'), ('u', 'g'), ('n', 'l'), ('p', 't'), ('y', 'd'), ('f', 's'), ('y', 'g'), ('t', 'l'), ('p', 'n'), ('d', 'm'), ('u', 'r'), ('a', 's'), ('l', 'd'), ('q', 'y'), ('p', 'u'), ('x', 'v'), ('l', 'g'), ('m', 'c'), ('b', 'i'), ('d', 'p'), ('t', 't'), ('k', 'z'), ('r', 'x'), ('h', 't'), ('h', 'n'), ('s', 'e'), ('s', 's'), ('s', 'h'), ('o', 'm'), ('e', 'y'), ('h', 'u'), ('x', 'n'), ('z', 'h'), ('w', 'n'), ('t', 'i'), ('g', 'n'), ('b', 'm'), ('m', 'e'), ('m', 'h'), ('c', 'm'), ('b', 'p'), ('z', 'a'), ('d', 'e'), ('d', 'h'), ('c', 'o'), ('p', 'p'), ('a', 'l'), ('s', 'w'), ('b', 'c'), ('m', 'a'), ('j', 'e'), ('t', 'm'), ('c', 'k'), ('f', 't'), ('v', 'o'), ('h', 'z'), ('j', 's'), ('c', 'c'), ('r', 't'), ('a', 'f'), ('k', 'e'), ('n', 'o'), ('z', 'd'), ('a', 't'), ('r', 'n'), ('k', 's'), ('t', 'p'), ('d', 'a'), ('m', 'w'), ('w', 'z'), ('f', 'u'), ('g', 'z'), ('s', 'r'), ('o', 'e'), ('s', 'l'), ('m', 'd'), ('y', 'o'), ('u', 'k'), ('b', 'e'), ('f', 'i'), ('s', 'f'), ('b', 'h'), ('d', 'd'), ('a', 'i'), ('m', 'r'), ('q', 't'), ('l', 'o'), ('d', 'g'), ('p', 'e'), ('q', 'n'), ('p', 's'), ('o', 'a'), ('p', 'h'), ('c', 'y'), ('d', 'r'), ('b', 'a'), ('t', 'e'), ('o', 'w'), ('f', 'm'), ('t', 'h'), ('c', 'a'), ('j', 'r'), ('n', 'y'), ('e', 't'), ('j', 'l'), ('h', 'e'), ('a', 'm'), ('b', 'w'), ('o', 'd'), ('e', 'n'), ('h', 's'), ('k', 'l'), ('f', 'p'), ('o', 'g'), ('u', 'y'), ('n', 'a'), ('b', 'd'), ('x', 's'), ('b', 'g'), ('y', 'y'), ('t', 'a'), ('w', 's'), ('o', 'r'), ('i', 's'), ('c', 'd'), ('c', 'g'), ('a', 'c'), ('b', 'r'), ('l', 'y'), ('s', 'm'), ('t', 'w'), ('x', 'x'), ('n', 'd'), ('i', 'x'), ('p', 'r'), ('b', 'f'), ('p', 'l'), ('t', 'd'), ('s', 'o'), ('t', 'g'), ('s', 'k'), ('p', 'f'), ('f', 'e'), ('s', 'c'), ('t', 'r'), ('f', 'h'), ('a', 'e'), ('m', 'o'), ('r', 's'), ('h', 'r'), ('a', 'h'), ('c', 'v'), ('h', 'l'), ('d', 'b'), ('t', 'f'), ('d', 'o'), ('l', 'x'), ('f', 'a'), ('w', 'l'), ('i', 'l'), ('d', 'k'), ('a', 'a'), ('j', 'p'), ('j', 'o'), ('k', 'o'), ('w', 't'), ('q', 's'), ('v', 't'), ('i', 't'), ('g', 't'), ('s', 'y'), ('a', 'w'), ('v', 'n'), ('k', 'k'), ('z', 'y'), ('f', 'd'), ('f', 'g'), ('o', 'o'), ('a', 'd'), ('b', 'b'), ('u', 't'), ('a', 'g'), ('s', 'a'), ('p', 'm'), ('b', 'o'), ('m', 'y'), ('f', 'r'), ('u', 'n'), ('o', 'c'), ('x', 'i'), ('f', 'l'), ('r', 'r'), ('c', 'b'), ('e', 's'), ('r', 'l'), ('y', 'n'), ('a', 'r'), ('b', 'k'), ('g', 'i'), ('p', 'o'), ('d', 'y'), ('f', 'f'), ('l', 't'), ('n', 'b'), ('p', 'k'), ('l', 'n'), ('s', 'd'), ('p', 'c'), ('s', 'g'), ('h', 'm'), ('k', 'h'), ('t', 'o'), ('x', 'm'), ('t', 'k'), ('h', 'o'), ('i', 'm'), ('g', 'm'), ('q', 'l'), ('j', 'a'), ('t', 'c'), ('k', 'a'), ('o', 'y'), ('h', 'c'), ('r', 'i'), ('w', 'p'), ('q', 'f'), ('g', 'p'), ('b', 'y'), ('d', 'x'), ('j', 'd'), ('p', 'y'), ('e', 'l'), ('k', 'd'), ('r', 'm'), ('p', 'a'), ('q', 'i'), ('t', 'y'), ('h', 'h'), ('f', 'o'), ('r', 'p'), ('w', 'e'), ('p', 'w'), ('a', 'o'), ('i', 'e'), ('g', 'e'), ('f', 'k'), ('w', 'h'), ('v', 's'), ('f', 'c'), ('g', 's'), ('g', 'h'), ('m', 't'), ('r', 'c'), ('a', 'k'), ('p', 'd'), ('h', 'a'), ('m', 'n'), ('p', 'g'), ('c', 'x'), ('e', 'i'), ('q', 'm'), ('d', 't'), ('u', 's'), ('s', 'b'), ('w', 'a'), ('d', 'n'), ('y', 's'), ('h', 'd'), ('w', 'w'), ('h', 'g'), ('l', 's'), ('r', 'e'), ('r', 'h'), ('w', 'd'), ('f', 'y'), ('i', 'd'), ('w', 'g'), ('i', 'g'), ('g', 'g'), ('a', 'y'), ('e', 'p'), ('o', 'n'), ('w', 'r'), ('v', 'r'), ('i', 'r'), ('g', 'r'), ('v', 'l'), ('r', 'a'), ('b', 'n'), ('g', 'l'), ('e', 'c'), ('c', 't'), ('k', 'b'), ('q', 'e'), ('w', 'f'), ('c', 'n'), ('b', 'u'), ('g', 'f'), ('q', 'h'), ('r', 'w'), ('u', 'l'), ('n', 't'), ('y', 'l'), ('n', 'n'), ('r', 'd'), ('r', 'g'), ('t', 'n'), ('c', 'i'), ('q', 'a'), ('l', 'r'), ('a', 'x'), ('e', 'e'), ('l', 'l'), ('y', 't'), ('e', 'h'), ('p', 'b'), ('z', 's'), ('n', 'i'), ('b', 'z'), ('t', 'b'), ('u', 'i'), ('e', 'a'), ('j', 'y'), ('m', 's'), ('k', 'y'), ('q', 'r'), ('v', 'm'), ('d', 's'), ('e', 'w'), ('c', 'p'), ('t', 'z'), ('l', 'i'), ('w', 'o'), ('e', 'd'), ('i', 'o'), ('g', 'o'), ('e', 'g'), ('f', 'n'), ('w', 'k'), ('a', 'n'), ('e', 'r'), ('u', 'p'), ('a', 'u'), ('o', 's'), ('z', 'l'), ('b', 's'), ('s', 't'), ('c', 'e'), ('l', 'p'), ('r', 'b'), ('m', 'l'), ('s', 'n'), ('c', 's'), ('c', 'h'), ('r', 'o'), ('h', 'y'), ('v', 'e'), ('l', 'c'), ('m', 'f'), ('s', 'u'), ('b', 'x'), ('v', 'h'), ('d', 'l'), ('n', 'e'), ('f', 'z'), ('w', 'y'), ('n', 's'), ('n', 'h'), ('i', 'y'), ('g', 'y')}
That's quite a few pairs! I'm easily amused by things like this, so let's see how many words are in the list which start with 'g' and end with 'y':
>>> gy = [j for j in fivers if j.startswith("g") and j.endswith("y")] >>> gy ['gabby', 'gaily', 'gamey', 'gassy', 'gaudy', 'gauzy', 'gawky', 'gayly', 'geeky', 'giddy', 'gimpy', 'gipsy', 'glory', 'gluey', 'godly', 'golly', 'goody', 'gooey', 'goofy', 'gouty', 'gravy', 'grimy', 'gully', 'gummy', 'gunny', 'guppy', 'gushy', 'gusty', 'gutsy', 'gypsy'] >>> len(gy) 30
Let's check the distribution (aren't buckets fun?) amongst all the start/end combinations:
>>> buckets = {} >>> for b in snend: ... buckets[b] = len([j for j in fivers if j.startswith(b[0]) and endswith(b[1])]) ...
I admit some surprise at seeing that there are 92 start/end combinations which only have one word in the list
>>> unobuckets = [b for b in buckets if buckets[b] == 1] >>> len(unobuckets) 92 >>> unobuckets [('a', 'z'), ('p', 'x'), ('z', 'i'), ('y', 'h'), ('t', 'x'), ('j', 'n'), ('h', 'x'), ('k', 'n'), ('d', 'i'), ('y', 'a'), ('v', 'g'), ('k', 'u'), ('j', 'i'), ('k', 'i'), ('u', 'g'), ('y', 'g'), ('q', 'y'), ('p', 'u'), ('x', 'v'), ('l', 'g'), ('b', 'i'), ('d', 'p'), ('k', 'z'), ('r', 'x'), ('h', 'u'), ('x', 'n'), ('z', 'a'), ('b', 'c'), ('h', 'z'), ('a', 'f'), ('n', 'o'), ('z', 'd'), ('f', 'u'), ('g', 'z'), ('y', 'o'), ('u', 'k'), ('f', 'i'), ('q', 'n'), ('o', 'w'), ('f', 'm'), ('j', 'l'), ('f', 'p'), ('o', 'g'), ('x', 's'), ('x', 'x'), ('c', 'v'), ('d', 'b'), ('t', 'f'), ('l', 'x'), ('j', 'p'), ('z', 'y'), ('b', 'b'), ('o', 'c'), ('g', 'i'), ('f', 'f'), ('n', 'b'), ('k', 'h'), ('i', 'm'), ('j', 'a'), ('h', 'c'), ('q', 'f'), ('d', 'x'), ('q', 'i'), ('r', 'p'), ('f', 'c'), ('q', 'm'), ('w', 'a'), ('w', 'w'), ('h', 'g'), ('i', 'g'), ('e', 'p'), ('e', 'c'), ('b', 'u'), ('r', 'w'), ('n', 't'), ('n', 'n'), ('q', 'a'), ('p', 'b'), ('n', 'i'), ('b', 'z'), ('u', 'i'), ('q', 'r'), ('v', 'm'), ('t', 'z'), ('l', 'i'), ('a', 'u'), ('z', 'l'), ('l', 'p'), ('r', 'b'), ('m', 'f'), ('s', 'u'), ('f', 'z')]
Let's choose five:
>>> for b in ("a", "z"), ("f", "z"), ("q", "n"), ("r", "x"), ("d", "x"): ... q = [j for j in fivers if j.startswith(b[0]) and j.endswith(b[1])] ... print(q) ... ['abuzz'] ['frizz'] ['queen'] ['relax'] ['detox']
I didn't really have a point to make here, I just wanted to share my amusement at how many five letter words there are to guess compared to the approximately 300 geographic entities on the planet that you'll shown the edges of in Worldle. Also that knowing Python means you can make short work of asking and answering these questions.