I've been actively interviewing over the last few months, and was recently talking with a cloud streaming provider about a Staff Engineer SRE role specializing in Apache Kafka. I've been doing a lot of work in that space for $employer and quite like it as a data streaming solution.
The interviews went well, and they sent me a do-at-home challenge with a one week timeout.
The gist of it was I had to create a Flask app which allowed the user to enter a URL to monitor for status on a given frequency, use Python to write a Kafka Producer to publish this data to a topic, and write a Kafka Consumer to read from the topic and insert into a PostgreSQL database.
Fun!
I did a brief investigation into using threads within a Flask app for the monitoring code, but quickly decided that a better architecture would be to do the monitoring via a separate daemon. Separation of concerns to allow for easier maintenance. Suddenly I'm all about ongoing maintenance rather then how quickly I can deliver a new feature... Hmmm.
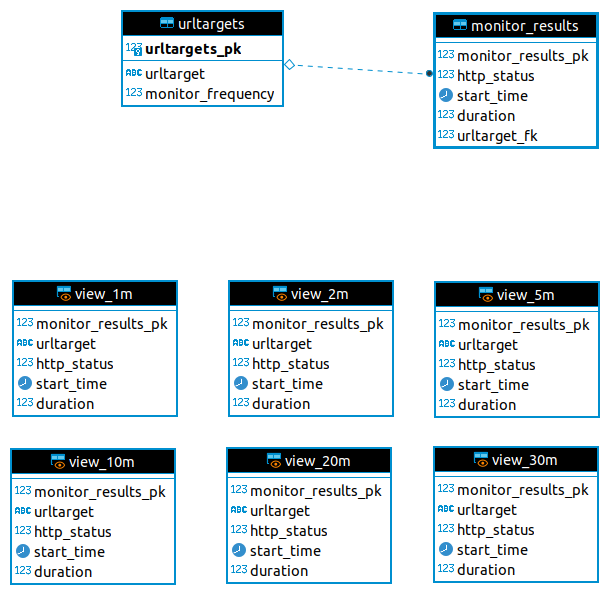
The next step was to sketch out the table schema I wanted in the database:
CREATE SEQUENCE public.urltargets_seq INCREMENT BY 1 MINVALUE 1 MAXVALUE 9223372036854775807 START 1 CACHE 1 NO CYCLE; CREATE SEQUENCE public.monitor_results_seq INCREMENT BY 1 MINVALUE 1 MAXVALUE 9223372036854775807 START 1 CACHE 1 NO CYCLE; CREATE TABLE IF NOT EXISTS urltargets ( urltargets_pk int4 NOT NULL DEFAULT nextval('urltargets_seq'::regclass), urltarget varchar(1024) NOT NULL, monitor_frequency int NOT NULL CHECK (monitor_frequency in (1, 2, 5, 10, 20, 30)), CONSTRAINT urltargets_pkey PRIMARY KEY (urltargets_pk) ); CREATE TABLE IF NOT EXISTS monitor_results ( monitor_results_pk int4 NOT NULL DEFAULT nextval('monitor_results_seq'::regclass), http_status int NOT NULL, start_time timestamp with time zone NOT NULL, duration int4 NOT NULL, urltarget_fk int4 NOT NULL, CONSTRAINT monitor_results_fk_fkey FOREIGN KEY (urltarget_fk) REFERENCES urltargets(urltargets_pk) );
Having decided that I would offer monitoring frequencies of 1, 2, 5, 10, 20 and 30 minutes, I created views for the Flask app to use as well, rather than direct queries. They all look like this, with other values substituted in as you would expect.
CREATE OR REPLACE VIEW view_1m as SELECT mr.monitor_results_pk , ut.urltarget , mr.http_status , mr.start_time , mr.duration FROM monitor_results mr JOIN urltargets ut on ut.urltargets_pk = mr.urltarget_fk WHERE ut.monitor_frequency = 1 ;
Since I really like seeing schemata visualised, I created a nice(ish) ERD as well:
Well that was straight forward, how about the application and daemon?
I split out the setup functionality into a separate file importable by the Flask app, the monitor daemon and the consumer. This contained the database connection, Kafka Producer and Kafka Consumer code. There's an interesting little niggle in the Kafka Producer setup which is not immediately obvious and required a bit of digging in StackOverflow as well as enabling debug output with librdkafka:
When I was working with the daemon, my first iteration tried opening the DB connection
and Producer in each thread's (one for each frequency) __init__() function, and .... that didn't work.
The DB connection is not picklable, so does _not_ survive the call to os.fork(). Once I had rewritten the
setup and run methods to get the DB connection, that part was groovy.
The Kafka Producer still required a bit of work. After reading through stackoverflow and the upstream for
librdkafka, I saw that I needed to similarly delay initialising the producer until the thread's
run() method was called. I also observed that each Producer should also initialise the transaction feature,
but leave the begin... end of the transaction to when it was called to publish a message.
I still had a problem, though - some transactions would get through, but then the Producer would be fenced. This was the niggle, and where the StackOverflow comments helped me out:
Finally, in distributed environments, applications will crash or —worse!— temporarily lose connectivity to the rest of the system. Typically, new instances are automatically started to replace the ones which were deemed lost. Through this process, we may have multiple instances processing the same input topics and writing to the same output topics, causing duplicate outputs and violating the exactly once processing semantics.
We call this the problem of “zombie instances.” [emphasis added]
I realised that I was giving the same transactional id to each of the six producer instances (setting
the 'transactional.id' in the configuration dict generated by _get_kafka_configuration(), so I needed
to uniqify them somehow. I decided to pass the monitoring frequency of the thread to the setup function,
and ... booyah, I had messages being published.
That was a really nice feeling.
There is one other aspect of the monitoring daemon that I need to mention. Since each thread reads its
list of URLs to monitor each time it wakes, I wanted to parallelize this effort. Monitoring each of
the URLs in series could easily take too long from a sleep(...) point of view, and I really did not
want to just fork a whole heap of processes and thread either - avoiding the potential for a fork-bomb.
To work around this I used the Python standard library concurrent.futures with a ThreadPoolExecutor
for each target URL. Adding attributes to the future object enabled me to use an add_done_callback
so that when the future crystallized it would then publish the message.
The check and publish methods are outside of the thread definition:
With the monitoring daemon written, I now needed the other end of the pipe - writing the
Kafka Consumer to read from the topic and insert into the database. This was straightforward:
we're polling for messages on both configured topics, when we read one we write it to the
appropriate DB table using a prepared statement, commit and then do it all again
with a while loop.
Of course there should be error handling for the execute(). There should also be packaging
and tests and templates for the report. Do not @ me, etc etc.
The reason why all these pieces are missing is because the day before I was due to hand this assignment in to my interviewer, I received a very, very nice offer from another company that I'd also been interviewing with - and I accepted it.