A few days ago I tweeted
Alt text:
Somebody asked (last ~week) something similar to "what questions do you always ask in an #software #engineering #interview?"
The response I saw (but failed to hit like on for bookmarking purposes) was "You hit X on the keyboard. What happens next?"
I was annoyed by this response for several reasons. So annoyed, in fact, that while we were away on a long-planned family holiday I lay awake one night thinking of the many ways which one could respond.
The "always ask" really got to me. Why is that particular question something that the interviewer always asks? Is it appropriate for every role? At what level and in how much detail do they expect the candidate to respond?
Thinking back to my very first encounter with a computer at all, it was an Apple //e at my primary school, early 1980s. You know the one, its user reference manual came with the complete circuit schematics and AppleBasic listing. I don't recall exactly how Apple handled the keyboard interface, but I'll punt and suggest that everything was hardwired....
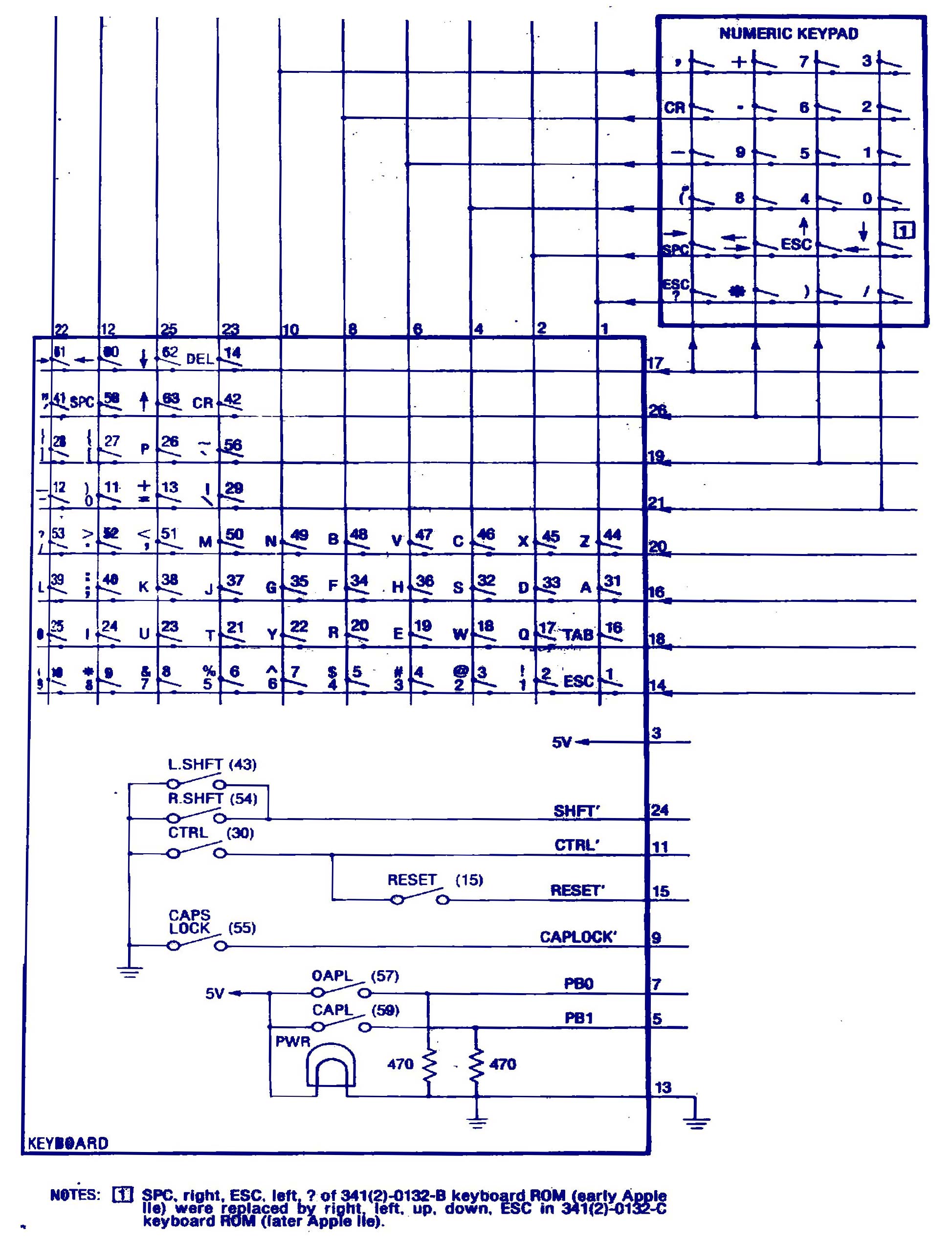
And it was. I found the Apple //e Hardware Schematics! If you piece together page 4, page 2 and the keyboard circuit schematic -- J17 is where the keyboard ribbon cable connects to the motherboard, and the circuit schematic shows very clearly that the keyboard is a row+column lookup. Very hard-wired.

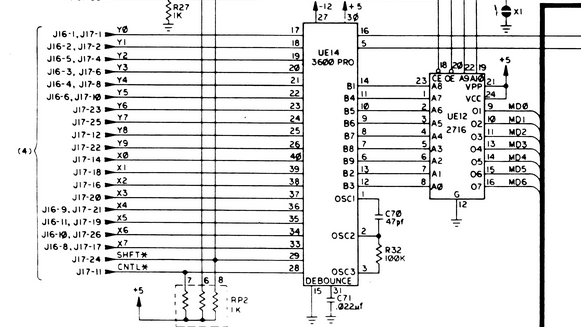
From the keyboard circuit schematic we see that key 'X' is on (20, 4) which maps to Y2 (pin 19 in UE14) and X3 (pin 31). The markings on UE14 are for the GI (General Instruments) AY-5-3600-PRO, which is a Keyboard Encoder.
From UE14 we go through UE12, the keyboard rom looks up the specific rendering for 'X', pushes that onto the main data bus and sends an interrupt to the 6502b cpu (see page 1 schematic). Then the relevant display function in ROM is invoked to push the actual "how to render this character" instructions into the video (NTSC or PAL) controller chip and thence to the physical display hardware.
By the way, you might be wondering what UE14 actually means. The 'U' means that the component is an integrated circuit, the E14 is an actual row+column lookup so you know where to look for it on the physical board.

It's somewhat obscured, but on the left of the pcb you can see a D and an E, while along the bottom you can see the numbers 1-15. This is a different pcb to what's in the schematics, because you can see that the 6502 is at E1 (so it would be UE1 on the schematic) while in the schematics I've found (see page 1) it's UC4.
Later, there were PCs with keyboards connected by a cable, and as it happens, there was a Intel 8042 inside as the microcontroller - which did pretty much the same thing as the entire Apple //e, except that the interrupt is generated by the Intel 8042 and sent out along the cable to the keyboard port on the main motherboard.... where again, an interrupt was generated and all the other lookups occurred prior to sending out to the display.
That's all well and good, but how about a more complicated system, like one of the many UNIXes such as Solaris. Or how about a minicomputer with hardwired terminals like a PDP-11? One of those hardwired terminals essentially used the same principles described above, but had a much more complicated kernel to push the data into. They also had local display buffer storage, so that wasn't something the kernel needed to worry about. What the kernel was interested in (please don't anthropomorphise computers, they hate it) was sending the keystrokes to the correct process.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}