Since I departed from my comfortable niche in Solaris engineering earlier
this year, I've spent a considerable amount of time and energy in re-training
and upskilling to assist my employment prospects. Apart from acquainting
myself with a lot of terminology, I've written code. A lot of code. Mostly, as
it turns out, has been related to microservices.
This post is about a microservice I wrote to assist with accessibility in a
specific part of the Australian electoral process (finding out which
electorate you live in) and some supporting digressions.
You can find all the code for this microservice and its associated data
preparation in my GitHub repos grabbag and find-my-electorate.
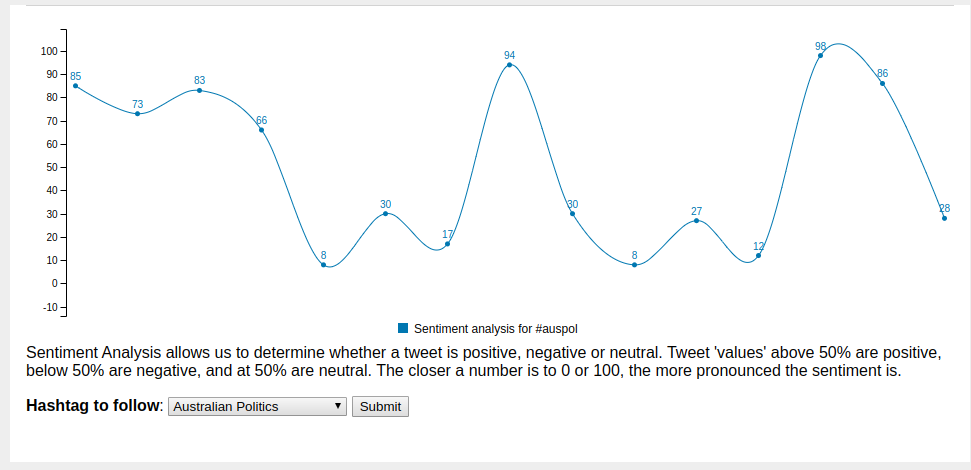
On 18 May 2019, Australia had a federal election, and in the lead up to
that event I became very interested in political polling. While I have a few
ideas on the subject which are on my back burner, mind-mapping the various
components of political polling got to wondering how do the various state,
territory and federal electoral commissions map a voter's address to an
electorate?
My first point of call was the Australian Electoral Commission and their
Find my electorate site. This is nicely laid out and lets you find out
which electorate you are in - by postcode. This is all well and good if you're
in a densely populated area, like the electorate of Brisbane - three
suburbs. If, however, you choose somewhere else, like 2620 which covers a
lot of Canberra and surrounding districts, you wind up with several
electorates covering 2620.
The AEC's website is written in asp.net, which is up to the task, but
when you have more than one page of results the authors of the page make use
of some (to my mind) squirrelly features and callbacks which make scraping the
site difficult. As best I can determine, the AEC doesn't provide an API to
access this information, so Another Method was required.
At this point, I turned to the standard libraries for this sort of thing in the
Python worldL Beautiful Soup and requests. I started by setting up a
quick venv to keep the dependencies contained
$ python3.7 -m venv scraping-venv
$ . scraping/bin/activate
(scraping-venv) $ pip install requests bs4 json csv
Now since we know the url to GET, we can get the first page of responses very
easily:
import requests
from bs4 import BeautifulSoup
url = "https://electorate.aec.gov.au/LocalitySearchResults.aspx?"
url += "filter={0}&filterby=Postcode"
result = requests.post(url.format(2620))
resh = BeautifulSoup(result.text, "html.parser")
Beautiful Soup parses the response text, and gives us a tree-like structure
to work with. Making use of the Chrome devtools (or the Firefox devtools )
I could see that I need to find a <table> with an attribute of
*ContentPlaceHolderBody_gridViewLocalities* - what a mouthful! - and then
process all the table rows (<tr>) within that table
tblAttr = "ContentPlaceHolderBody_gridViewLocalities"
restbl = resh.find_all(name="table", attrs={"id": tblAttr})
rows = restbl[0].find_all("tr")
Using a for loop we can construct a dict of the data that we actually
need. Simple!
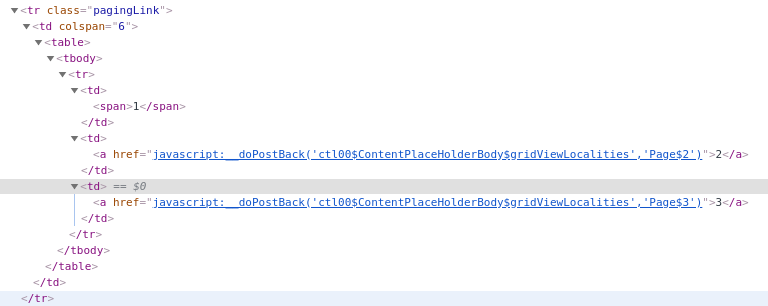
What do we do, though, when we want to get the second or later pages of
result? This is where the squirrelly features and callbacks come in. The page
makes use of an __EVENTARGUMENT element which is POST ed as payload
back to the same url. The way that we determine this is to look for a row with
the class pagingLink, then for each table data (<td>) element check
for its contents matching this regex
".*__doPostBack.'(.*?gridViewLocalities)','(Page.[0-9]+)'.*")
And after that we can recursively call our query with the extra payload data
in the argument list:
def queryAEC(postcode, extrapage):
"""
Queries the AEC url and returns soup. If extrapage is empty
then we pass the soup to findFollowups before returning.
"""
url = "https://electorate.aec.gov.au/LocalitySearchResults.aspx?"
url += "filter={0}&filterby=Postcode"
if not extrapage:
res = requests.post(url.format(postcode))
else:
payload["__EVENTARGUMENT"] = extrapage
res = requests.post(url.format(postcode), data=payload)
I now had a script to run which extracted this info and pretty-printed it
(as well as the same info in JSON):
$ ./postcode.py 2620
State Postcode Locality Electorate
ACT 2620 BEARD Canberra
ACT 2620 BOOTH DISTRICT Bean
NSW 2620 BURRA Eden-Monaro
NSW 2620 CARWOOLA Eden-Monaro
NSW 2620 CLEAR RANGE Eden-Monaro
ACT 2620 CORIN DAM Bean
NSW 2620 CRESTWOOD Eden-Monaro
NSW 2620 ENVIRONA Eden-Monaro
NSW 2620 FERNLEIGH PARK Eden-Monaro
NSW 2620 GOOGONG Eden-Monaro
NSW 2620 GREENLEIGH Eden-Monaro
NSW 2620 GUNDAROO Eden-Monaro
ACT 2620 HUME Bean
NSW 2620 KARABAR Eden-Monaro
ACT 2620 KOWEN DISTRICT Canberra
ACT 2620 KOWEN FOREST Canberra
NSW 2620 MICHELAGO Eden-Monaro
ACT 2620 OAKS ESTATE Canberra
ACT 2620 PADDYS RIVER DISTRICT Bean
NSW 2620 QUEANBEYAN Eden-Monaro
NSW 2620 YARROW Eden-Monaro
NSW 2620 QUEANBEYAN EAST Eden-Monaro
NSW 2620 QUEANBEYAN WEST Eden-Monaro
NSW 2620 RADCLIFFE Eden-Monaro
ACT 2620 RENDEZVOUS CREEK DISTRICT Bean
ACT 2620 ROYALLA Bean
NSW 2620 ROYALLA Eden-Monaro
NSW 2620 SUTTON Eden-Monaro
ACT 2620 TENNENT DISTRICT Bean
ACT 2620 THARWA Bean
NSW 2620 THARWA Eden-Monaro
NSW 2620 THARWA Eden-Monaro
NSW 2620 THE ANGLE Eden-Monaro
NSW 2620 THE RIDGEWAY Eden-Monaro
NSW 2620 TINDERRY Eden-Monaro
NSW 2620 TRALEE Eden-Monaro
ACT 2620 TUGGERANONG DISTRICT Bean
NSW 2620 URILA Eden-Monaro
NSW 2620 WAMBOIN Eden-Monaro
ACT 2620 WILLIAMSDALE Bean
NSW 2620 WILLIAMSDALE Eden-Monaro
That really is quite a few suburbs.
So now that we've got a way to extract that information, how do we make it
available and useful for everybody? With a microservice! I hear you cry.
The very first microservice I wrote (in 2011-12, the subject of a future
post) used CherryPy, because we'd embedded it within Solaris IPS (image
packaging system) and didn't need any further corporate approvals. The path of
least resistance. This time, however, I was unconstrained regarding approvals,
so had to choose between Django and flask. For no particular reason, I
chose flask.
It was pretty easy to cons up the requisite templates, and write the
/results method. It was at this point that my extend the fix habit
(learnt via the Kepner-Tregoe Analytical Troubleshooting training many
years ago) kicked in, and I started exploring the Electoral Commission of
Queensland website for the same sort of information. To my surprise, the
relatively straight-forward interface of the AEC was not available, and the
closest analogue was an interactive map.
After a brief phone conversation with ECQ and more digging, I discovered
that the 2017 boundaries were available from QLD Spatial in shapefile,
MapInfo and Google Maps KML formats. This was very useful, because KML can be
mucked about with directly using Beautiful Soup. After not too much effort I
had the latitude+longitude pairs for the boundaries extracted and stored as
JSON . My phone conversation with ECQ also took me down the path
of wanting to translate a street address into GeoJSON - and that took me
to the Google Maps API. I did investigate OpenStreetMap's api, but
testing a few specific locations (addresses where we've lived over the
years) gave me significantly different latitude+longitude results. I bit the
bullet and got a Google Maps API key .
The next step was to research how to find out if a specific point is located
within a polygon, and to my delight the Even-odd rule has example code
in Python, which needed only a small change to work with my data
arrangement.
With that knowledge in hand, it was time to turn the handle on the
Google Maps API :
keyarg = "&key={gmapkey}"
queryurl = "https://maps.googleapis.com/maps/api/geocode/json?address="
queryurl += "{addr} Australia"
queryurl += keyarg
...
# Helper functions
def get_geoJson(addr):
"""
Queries the Google Maps API for specified address, returns
a dict of the formatted address, the state/territory name, and
a float-ified version of the latitude and longitude.
"""
res = requests.get(queryurl.format(addr=addr, gmapkey=gmapkey))
dictr = {}
if res.json()["status"] == "ZERO_RESULTS" or not res.ok:
dictr["res"] = res
else:
rresj = res.json()["results"][0]
dictr["formatted_address"] = rresj["formatted_address"]
dictr["latlong"] = rresj["geometry"]["location"]
for el in rresj["address_components"]:
if el["types"][0] == "administrative_area_level_1":
dictr["state"] = el["short_name"]
return dictr
When you provide an address, we send that to Google which does a best-effort
match on the text address then returns GeoJSON for that match. For example,
if you enter
42 Wallaby Way, Sydney
the best-effort match will give you
42 Rock Wallaby Way, Blaxland NSW 2774, Australia
I now had a way to translate a street address into a federal electorate, but
with incomplete per-State data my app wasn't finished. I managed to get
Federal, Queensland, New South Wales, Victoria and Tasmania data fairly easily
(see the links below) and South Australia's data came via personal email after
an enquiry through their contact page. I didn't get any response to several
contact attempts with either Western Australia or the Northern Territory, and
the best I could get for the ACT was their electorate to suburb associations.
I remembered that the Australian Bureau of Statistics has a standard
called Statistical Geography, and the smallest unit of that is called a
Mesh Block:
Mesh Blocks (MBs) are the smallest geographical area defined by the
ABS. They are designed as geographic building blocks rather than as areas
for the release of statistics themselves. All statistical areas in the
ASGS, both ABS and Non ABS Structures, are built up from Mesh Blocks. As a
result the design of Mesh Blocks takes into account many factors including
administrative boundaries such as Cadastre, Suburbs and Localities and
LGAs as well as land uses and dwelling distribution.
(emphasis added)
Mesh Blocks are then aggregated into SA1s:
Statistical Areas Level 1 (SA1s) are designed to maximise the spatial
detail available for Census data. Most SA1s have a population of between
200 to 800 persons with an average population of approximately 400
persons. This is to optimise the balance between spatial detail and the
ability to cross classify Census variables without the resulting counts
becoming too small for use. SA1s aim to separate out areas with different
geographic characteristics within Suburb and Locality boundaries. In rural
areas they often combine related Locality boundaries. SA1s are
aggregations of Mesh Blocks.
(emphasis added)
With this knowledge, and a handy SA1-to-postcode map in CSV format
$ head australia-whole/SED_2018_AUST.csv
SA1_MAINCODE_2016,SED_CODE_2018,SED_NAME_2018,STATE_CODE_2016,STATE_NAME_2016,AREA_ALBERS_SQKM
10102100701,10031,Goulburn,1,New South Wales,362.8727
10102100702,10053,Monaro,1,New South Wales,229.7459
10102100703,10053,Monaro,1,New South Wales,2.3910
10102100704,10053,Monaro,1,New South Wales,1.2816
10102100705,10053,Monaro,1,New South Wales,1.1978
....
I went looking into the SA1 information from the ABS shapefile covering the
whole of the country. Transforming the shapefile into kml is done with
ogr2ogr and provides us with an XML schema definition. From the CSV header
line above we can see that we want the SA1_MAINCODE_2016 and (for
validation) the STATE_NAME_2016 fields. Having made a per-state list of
the SA1s, we go back to the kml and process each member of the document:
<gml:featureMember>
<ogr:SED_2018_AUST fid="SED_2018_AUST.0">
<ogr:geometryProperty>
<gml:Polygon srsName="EPSG:4283">
<gml:outerBoundaryIs>
<gml:LinearRing>
<gml:coordinates>
....
</gml:coordinates>
</gml:LinearRing>
</gml:outerBoundaryIs>
</gml:Polygon>
</gml:polygonMember>
</ogr:geometryProperty>
<ogr:SED_CODE18>30028</ogr:SED_CODE18>
<ogr:SED_NAME18>Gladstone</ogr:SED_NAME18>
<ogr:AREASQKM18>2799.9552</ogr:AREASQKM18>
</ogr:SED_2018_AUST>
</gml:featureMember>
The gml:coordinates are what we really need, they're space-separated
lat,long pairs.
for feature in sakml.findAll("gml:featureMember"):
sa1 = feature.find("ogr:SA1_MAIN16").text
mb_coord[sa1] = mb_to_points(feature)
for block in mb_to_sed:
electorate = mb_to_sed[block]
sed_to_mb[electorate]["coords"].extend(mb_coord[block])
After which we can write each jurisdiction's dict of localities and lat/long
coordinates out as JSON using json.dump(localitydict, outfile).
To confirm that I had the correct data, I wrote another simple quick-n-dirty
script jsoncheck.py to diff the SA1-acquired JSON against my other
extractions. There was one difference of importance found - Queensland has a
new electorate McConnel, which was created after the most recent ABS SA1
allocation.
So that's the data preparation done, back to the flask app! The app listens
at the root (/), and is a simple text form. Hitting enter after typing
in an address routes the POST request to the results function where we
call out to the Google Maps API, load the relevant state JSONified
electorate list, and then locate the Federal division. There are 151 Federal
divisions, so it's not necessarily a bad thing to search through each on an
alphabetic basis and break when we get a match. I haven't figured out a way to
(time and space)-efficiently hash the coordinates vs divisions. After
determining the Federal division we then use the same method to check against
the identified state's electorate list.
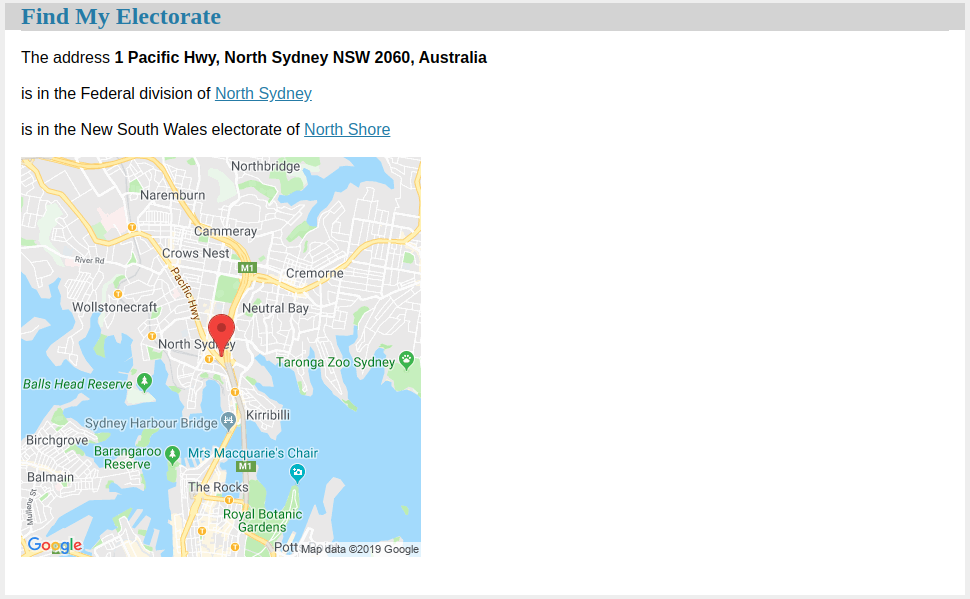
The first version of the app just returned the two electorate names, but I
didn't think that was very friendly, so I added another call to the
Google Maps API to retrieve a 400x400 image showing the supplied address on
the map; clicking on that map takes you to the larger Google-hosted map. I
also added links to the Wikipedia entries for the Federal and state
electorates. To render the image's binary data we use b64encode:
from base64 import b64encode
keyarg = "&key={gmapkey}"
imgurl = "https://maps.googleapis.com/maps/api/staticmap?size=400x400"
imgurl += "¢er={lati},{longi}&scale=1&maptype=roadmap&zoom=13"
imgurl += "&markers=X|{lati},{longi}"
imgurl += keyarg
# Let's provide a Google Maps static picture of the location
# Adapted from
# https://stackoverflow.com/questions/25140826/generate-image-embed-in-flask-with-a-data-uri/25141268#25141268
#
def get_image(latlong):
"""
latlong -- a dict of the x and y coodinates of the location
Returns a base64-encoded image
"""
turl = imgurl.format(longi=latlong["lng"],
lati=latlong["lat"],
gmapkey=gmapkey)
res = requests.get(turl)
return b64encode(res.content)
....
# and in the results function
img_data = get_image(dictr["latlong"])
return render_template("results.html",
...,
img_data=format(quote(img_data))
...)
Putting that all together gives us a rendered page that looks like this:
To finalise the project, I ran it through flake8 again (I do this every few
saves), and then git commit followed by git push.
Reference data locations
Tasmania's state parliament has multi-member electorates, which have the same
boundaries as their 5 Federal divisions.
South Australia data was provided via direct personal email.
Australian Capital Territory, Western Australia and Northern Territory data
was extracted from the ABS shapefile after ogr2ogr-converting from
MapInfo Interchange Format.