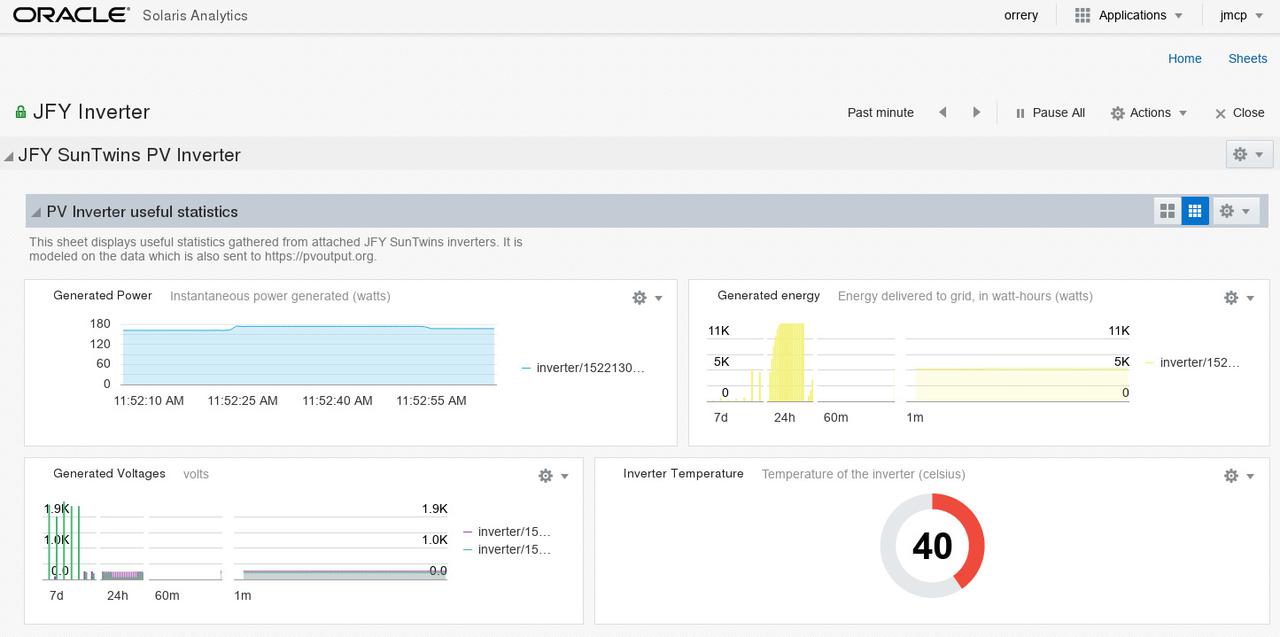
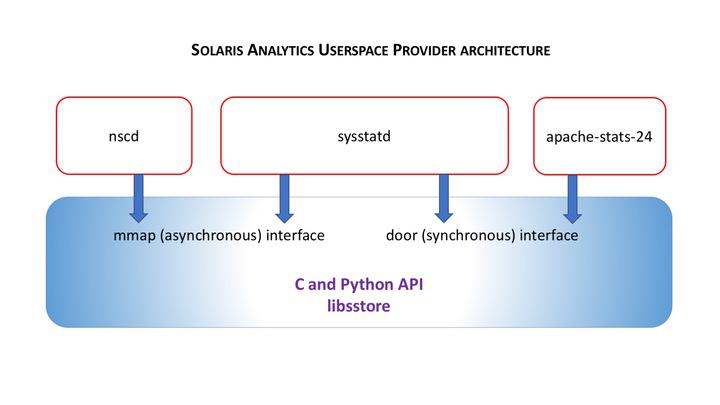
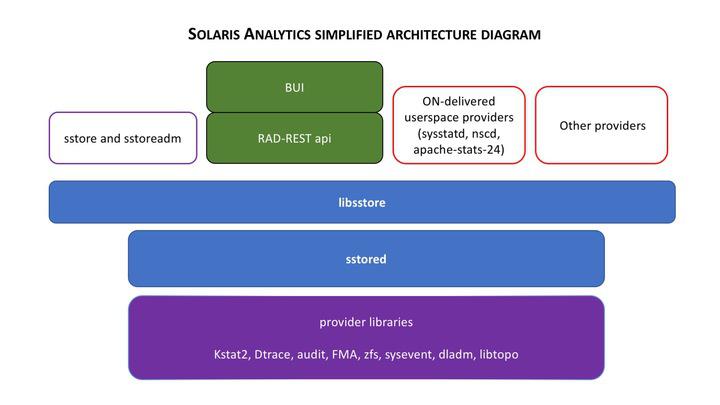
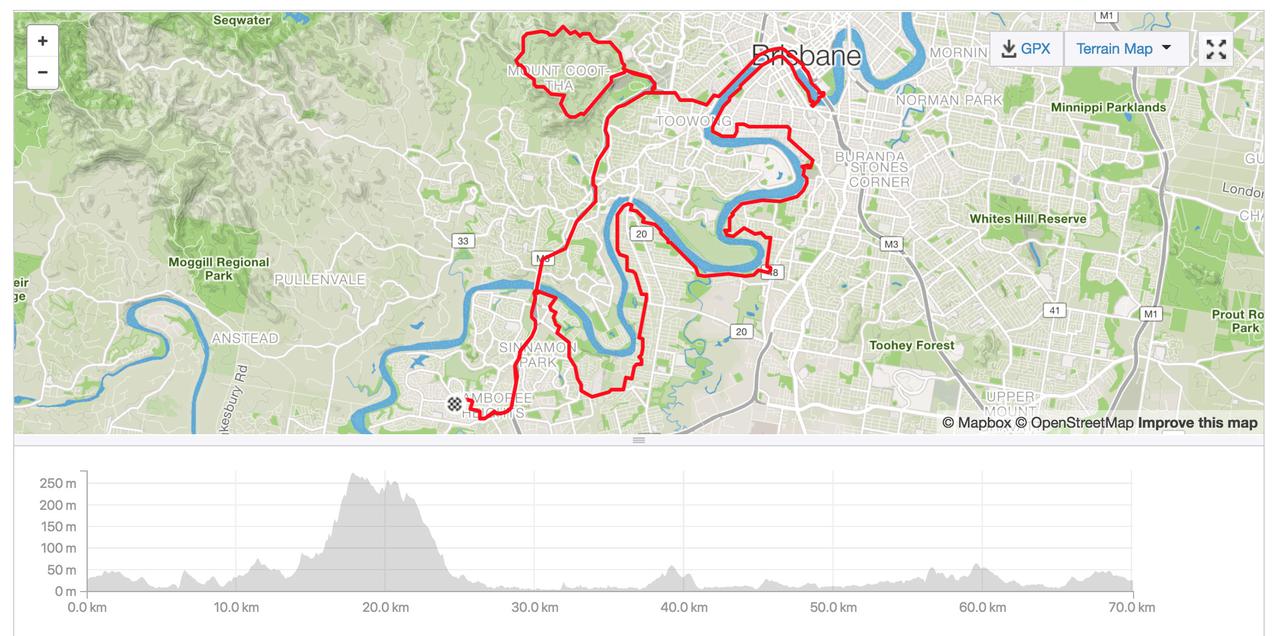
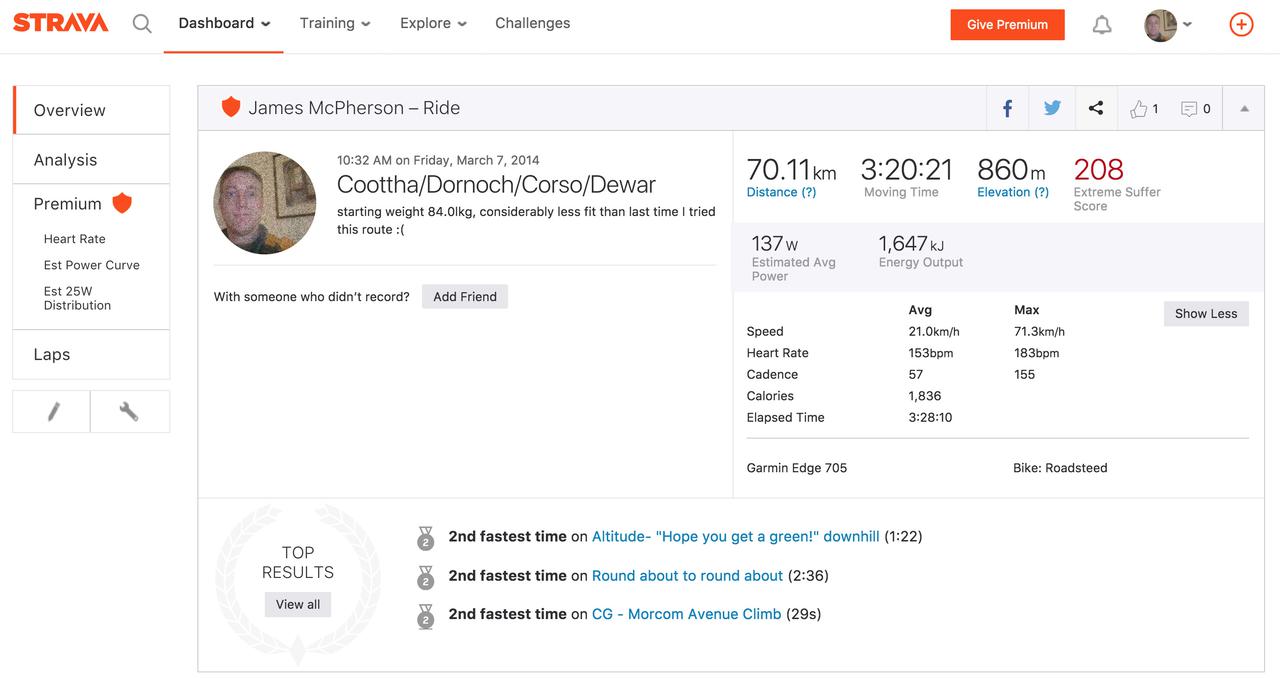
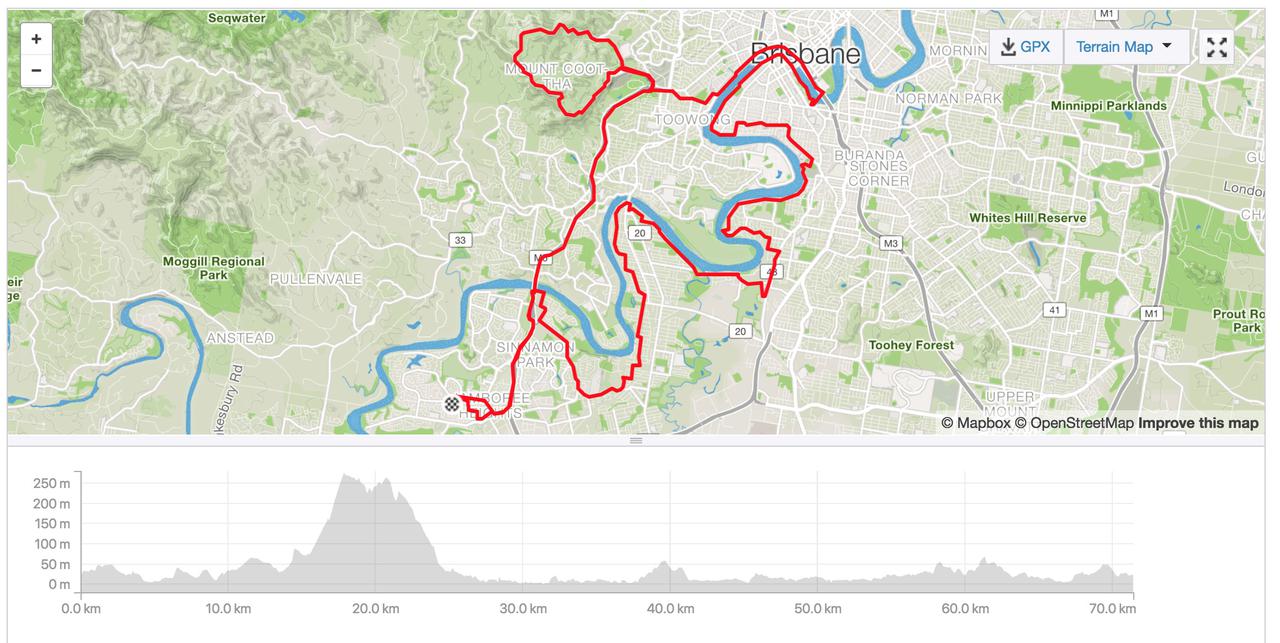
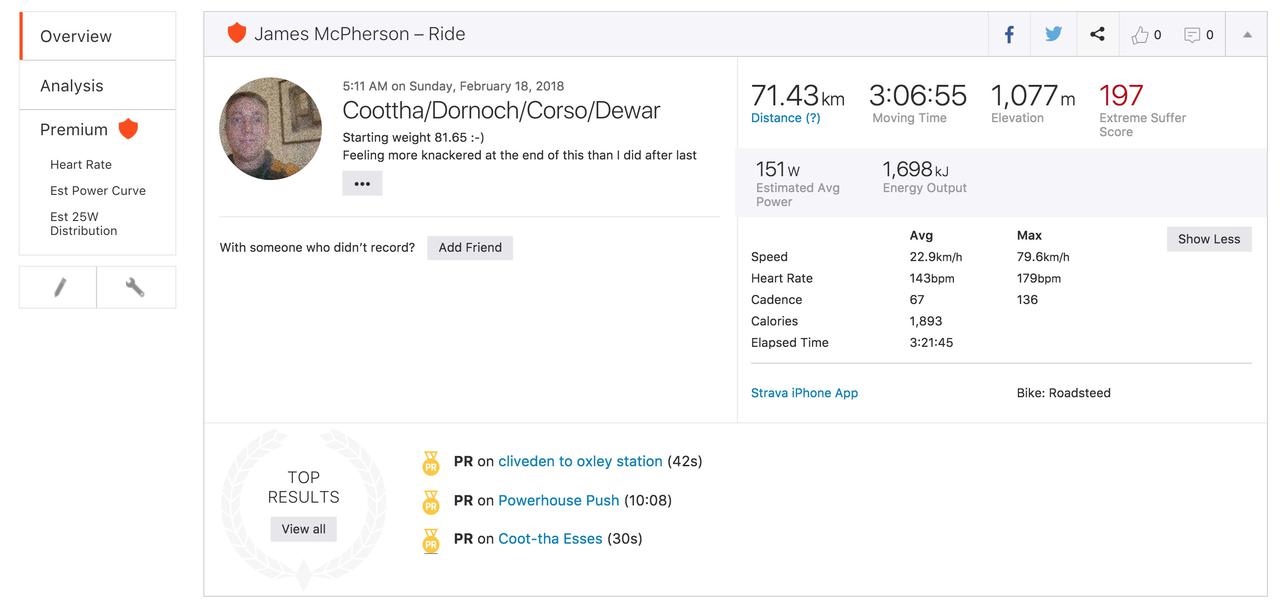
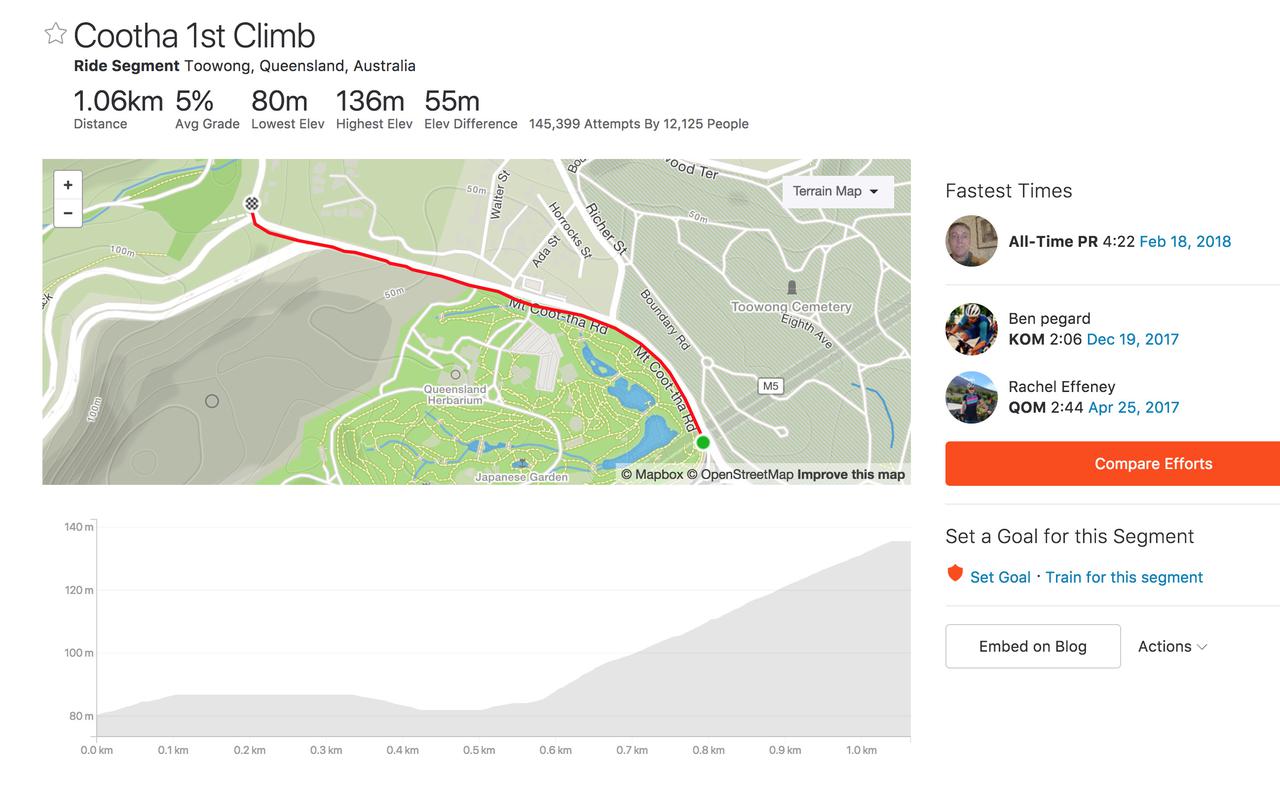
Every now and again I see firefox taking up an entire core on my
workstation. Today's thread of interest is #1:
$ pstack 19575
19575: /usr/lib/firefox/firefox
------------ lwp# 1 / thread# 1 ---------------
f21bf265 mmap (1000000, fa9d97f0, 0, 806df3a, 0, 0) + 15
0806df3a huge_palloc (8084b40, 34000000, 55600000, 807006d, e54bd608, bb03e498) + 64
0807006d je_realloc (e54bd608, e35fc0a0, 19504, 80693c9) + 8ee
080693c9 realloc (cde84f80, cde84f81, 6020e100, f159bcc2) + 45
f159bcc2 _ZN2js9MarkStack7enlargeEj (76d29960, e54bd608, fa9d9968, f15a1308) + 58
f15a1308 _ZN2js8GCMarker8traverseIP8JSObjectEEvT_ (e54bd608, e54bd608, fa9d99b8, f15aa837, e54bd608, 76d29960) + 42
f15aa837 _Z9DoMarkingI8JSObjectEvPN2js8GCMarkerEPT_ (f16b8000, dc54f064, fa9d99f8, f15b710d) + 39
f15b710d _Z9DoMarkingIN2JS5ValueEEvPN2js8GCMarkerERKT_ (f16b8000, fa9d9ab0, fa9d9a28, f15b718e) + 42
f15b718e _Z16DispatchToTracerIN2JS5ValueEEvP8JSTracerPT_PKc (e54bd608, fa9d9ab0, ee3e9323, f15b71e2) + 38
f15b71e2 _ZN2js9TraceEdgeIN2JS5ValueEEEvP8JSTracerPNS_18WriteBarrieredBaseIT_EEPKc (e54bd608, e350fee0, ee30859c, f10d79e8, e54bd608, 3a7715a0) + 1e
f10d79e8 _ZN2js9MapObject4markEP8JSTracerP8JSObject (fa9d9de8, e54bd608, fa9d9b78, f15a4883) + 1c0
f15a4883 _ZN2js8GCMarker14drainMarkStackERNS_11SliceBudgetE (fa9d9b98, 0, 4378ac, f13376b7, e54bd608, fa9d9de8) + 4b3
f13376b7 _ZN2js2gc9GCRuntime14drainMarkStackERNS_11SliceBudgetENS_7gcstats5PhaseE (f148e7e5, fa9d9c1c, e54bb4f0, f1350f5b) + 3f
f1350f5b _ZN2js2gc9GCRuntime23incrementalCollectSliceERNS_11SliceBudgetEN2JS8gcreason6ReasonERNS_26AutoLockForExclusiveAccessE (568bb, 3e8, 5, f1351bff, e54bb4f0, fa9d9de8) + 26d
f1351bff _ZN2js2gc9GCRuntime7gcCycleEbRNS_11SliceBudgetEN2JS8gcreason6ReasonE (fa9d9dc8, f1351e33, 5abff385, f1351e9e, e54bb4f0, 0) + 25d
f1351e9e _ZN2js2gc9GCRuntime7collectEbNS_11SliceBudgetEN2JS8gcreason6ReasonE (f16b8000, f1b24820, fa9d9e00, f135223e, e54bb4f0, 0) + 16e
f135223e _ZN2js2gc9GCRuntime7startGCE18JSGCInvocationKindN2JS8gcreason6ReasonEx (0, 0, fa9d9ea0, f13523b7, e54bb4f0, 0) + 8c
f13523b7 _ZN2js2gc9GCRuntime13gcIfRequestedEv (e2f2b000, fa9d9ed8, fa9d9ee0, f1457b6b) + 55
f1457b6b _ZN2js23InternalCallOrConstructEP9JSContextRKN2JS8CallArgsENS_14MaybeConstructE (fa9da250, fa9ddead, fa9d9f60, f1457c03) + 292
f1457c03 _ZL12InternalCallP9JSContextRKN2js13AnyInvokeArgsE (e54bb000, e2f26c38, ffffff8c, f1457c7c, fa9da0a4, e4a253d8) + 87
f1457c7c _ZN2js4CallEP9JSContextN2JS6HandleINS2_5ValueEEES5_RKNS_13AnyInvokeArgsENS2_13MutableHandleIS4_EE (e4a25280, f1b24818, fa9da0a4, f13b4fb4, e54bb000, fa9da0c8) + 46
f13b4fb4 _ZNK2js7Wrapper4callEP9JSContextN2JS6HandleIP8JSObjectEERKNS3_8CallArgsE (fa9da250, fa9da518, 1, f13a8784) + 200
f13a8784 _ZNK2js23CrossCompartmentWrapper4callEP9JSContextN2JS6HandleIP8JSObjectEERKNS3_8CallArgsE (fa9da278, fa9da260, fa9da1a8, f13a6de3) + 104
f13a6de3 _ZN2js5Proxy4callEP9JSContextN2JS6HandleIP8JSObjectEERKNS3_8CallArgsE (e2d59c70, e54bb000, fa9da2d8, f13a7809, e54bb000, fa9da1f0) + eb
f13a7809 _ZN2js10proxy_CallEP9JSContextjPN2JS5ValueE (4, e54bb000, 0, f14579ba) + 60
f14579ba _ZN2js23InternalCallOrConstructEP9JSContextRKN2JS8CallArgsENS_14MaybeConstructE (fa9da660, 6eabb3c0, f1b24834, f1457c03) + e1
f1457c03 _ZL12InternalCallP9JSContextRKN2js13AnyInvokeArgsE (651d54b0) + 87
f1457c2d _ZN2js13CallFromStackEP9JSContextRKN2JS8CallArgsE (0, 0, 0, f1652df7) + 1b
f1652df7 _ZN2js3jitL14DoCallFallbackEP9JSContextPNS0_13BaselineFrameEPNS0_15ICCall_FallbackEjPN2JS5ValueENS7_13MutableHandleIS8_EE (0, f1b24828, 0, 2a74025f, e54bb000, fa9da578) + 4a7
2a74025f ???????? (2acf6833, 8021, 7b460c70, ffffff8c, 7b460c60, ffffff8c)
651d54d0 ???????? (3444, e2d5f940, 4, d9d5d910, ffffff8c, 62e048c0)
2a73f909 ???????? (2acf6370, 5, fa9daa18, 0, e2d5f940, 0)
f162d642 _ZL13EnterBaselineP9JSContextRN2js3jit12EnterJitDataE (e54bb000, fa9da718, fa9da880, f1630993, e35cf448, f19105ac) + 15b
f1630993 _ZN2js3jit19EnterBaselineMethodEP9JSContextRNS_8RunStateE (e54bb000, fa9da7dc, fa9da880, f1457837) + 10b
f1457837 _ZN2js9RunScriptEP9JSContextRNS_8RunStateE (e2f2b000, fa9da868, fa9da870, f1457b3c, e54bb000, fa9da880) + 2d7
f1457b3c _ZN2js23InternalCallOrConstructEP9JSContextRKN2JS8CallArgsENS_14MaybeConstructE (e54bb000, fa9ddead, fa9da8f0, f1457c03) + 263
f1457c03 _ZL12InternalCallP9JSContextRKN2js13AnyInvokeArgsE (e54bb000, e31e9438, ffffff8c, f1457c7c, fa9daa34, e4a252e8) + 87
f1457c7c _ZN2js4CallEP9JSContextN2JS6HandleINS2_5ValueEEES5_RKNS_13AnyInvokeArgsENS2_13MutableHandleIS4_EE (e4a25280, f1b24818, fa9daa34, f13b4fb4, e54bb000, fa9daa58) + 46
f13b4fb4 _ZNK2js7Wrapper4callEP9JSContextN2JS6HandleIP8JSObjectEERKNS3_8CallArgsE (f1b24800, e2d07190, fa9daa98, f13a8784) + 200
f13a8784 _ZNK2js23CrossCompartmentWrapper4callEP9JSContextN2JS6HandleIP8JSObjectEERKNS3_8CallArgsE (e487ac10, fa9dab8c, f257263e, f13a6de3) + 104
f13a6de3 _ZN2js5Proxy4callEP9JSContextN2JS6HandleIP8JSObjectEERKNS3_8CallArgsE (e2d5f940, e54bb000, fa9dac68, f13a7809, e54bb000, fa9dab80) + eb
f13a7809 _ZN2js10proxy_CallEP9JSContextjPN2JS5ValueE (4, e54bb000, 0, f14579ba) + 60
f14579ba _ZN2js23InternalCallOrConstructEP9JSContextRKN2JS8CallArgsENS_14MaybeConstructE (fa9dafb0, 79c58750, f1b24834, f1457c03) + e1
f1457c03 _ZL12InternalCallP9JSContextRKN2js13AnyInvokeArgsE (e54be37c) + 87
f1457c2d _ZN2js13CallFromStackEP9JSContextRKN2JS8CallArgsE (0, 0, 0, f1652df7) + 1b
f1652df7 _ZN2js3jitL14DoCallFallbackEP9JSContextPNS0_13BaselineFrameEPNS0_15ICCall_FallbackEjPN2JS5ValueENS7_13MutableHandleIS8_EE (fa9daed8, f1b24820, fa9db1d8, 2a74025f, e54bb000, fa9daed8) + 4a7
2a74025f ???????? (2acf59f4, 5821, 7ae939a0, ffffff8c, 52cd2840, ffffff8c)
648bf320 ???????? (2444, d9d40a80, 1, 0, ffffff82, 7b858a60)
2a73f909 ???????? (2acf5680, 2, fa9db368, 0, d9d40a80, 0)
f162d642 _ZL13EnterBaselineP9JSContextRN2js3jit12EnterJitDataE (e54bb000, fa9db068, fa9db1d0, f1630993, e2d104f0, f16e0134) + 15b
f1630993 _ZN2js3jit19EnterBaselineMethodEP9JSContextRNS_8RunStateE (e54bb000, fa9db12c, fa9db1d0, f1457837) + 10b
f1457837 _ZN2js9RunScriptEP9JSContextRNS_8RunStateE (d6ec4800, f16b8000, fa9db1c0, f1457b3c, e54bb000, fa9db1d0) + 2d7
f1457b3c _ZN2js23InternalCallOrConstructEP9JSContextRKN2JS8CallArgsENS_14MaybeConstructE (fa9db3ac, 238be150, fa9db240, f1457c03) + 263
f1457c03 _ZL12InternalCallP9JSContextRKN2js13AnyInvokeArgsE (e54bb000, e2f2b038, ffffff82, f1457c7c, fa9db384, e4a25208) + 87
f1457c7c _ZN2js4CallEP9JSContextN2JS6HandleINS2_5ValueEEES5_RKNS_13AnyInvokeArgsENS2_13MutableHandleIS4_EE (e4a24fb8, f1b24818, fa9db384, f13b4fb4, e54bb000, fa9db3a8) + 46
f13b4fb4 _ZNK2js7Wrapper4callEP9JSContextN2JS6HandleIP8JSObjectEERKNS3_8CallArgsE (fa9db5ec, fa9db8a8, fa9db400, f13a8784) + 200
f13a8784 _ZNK2js23CrossCompartmentWrapper4callEP9JSContextN2JS6HandleIP8JSObjectEERKNS3_8CallArgsE (e4a25088, 84, fa9db470, f13a6de3) + 104
f13a6de3 _ZN2js5Proxy4callEP9JSContextN2JS6HandleIP8JSObjectEERKNS3_8CallArgsE (d9d40a80, e54bb000, fa9db4d0, f13a7809, e54bb000, fa9db4d0) + eb
f13a7809 _ZN2js10proxy_CallEP9JSContextjPN2JS5ValueE (e4a25088, ffffff8c, fa9db520, f14579ba) + 60
f14579ba _ZN2js23InternalCallOrConstructEP9JSContextRKN2JS8CallArgsENS_14MaybeConstructE (fa9db71c, 1, fa9db608, f1457c03) + e1
f1457c03 _ZL12InternalCallP9JSContextRKN2js13AnyInvokeArgsE (d9d40a80, fa9db720, ffffff82, f1457c7c, fa9db5fc, fa9db5f0) + 87
f1457c7c _ZN2js4CallEP9JSContextN2JS6HandleINS2_5ValueEEES5_RKNS_13AnyInvokeArgsENS2_13MutableHandleIS4_EE (e54bb000, 29, fa9db738, f145c065, e54bb000, fa9db7d8) + 46
f145c065 _ZN2js19SpreadCallOperationEP9JSContextN2JS6HandleIP8JSScriptEEPhNS3_INS2_5ValueEEES9_S9_S9_NS2_13MutableHandleIS8_EE (e54bb000, fa9db760, 54df14a0, f1652875, e54bb000, fa9db7fc) + 427
f1652875 _ZN2js3jitL20DoSpreadCallFallbackEP9JSContextPNS0_13BaselineFrameEPNS0_15ICCall_FallbackEPN2JS5ValueENS7_13MutableHandleIS8_EE (f1b24820, fa9db834, e35d5d00, 2a7401e8, e54bb000, fa9db8d8) + 237
2a7401e8 ???????? (2ae0c852, 4021, 7b858a90, ffffff8c, 0, ffffff82)
54df14a0 ???????? (2042, d9d3f0d0, 1, 0, ffffff82, 7b858a90)
2ab50cd4 ???????? (2acf0414, 4821, 7b858af0, ffffff8c, 0, ffffff82)
5ddfe7a8 ???????? (2042, e2d5b080, 2, 0, ffffff82, d9d3f0d0)
2ab50cd4 ???????? (2acd3bc4, 4821, 7b858b50, ffffff8c, 0, ffffff82)
51417888 ???????? (3444, e2d5b060, 3, 0, ffffff82, d9d36c60)
2a73f909 ???????? (2acd34d0, 4, fa9dbe78, 0, e2d5b060, 0)
f162d642 _ZL13EnterBaselineP9JSContextRN2js3jit12EnterJitDataE (e54bb000, fa9dbb78, fa9dbce0, f1630993, 2422, 1) + 15b
f1630993 _ZN2js3jit19EnterBaselineMethodEP9JSContextRNS_8RunStateE (e54bb000, fa9dbc3c, fa9dbce0, f1457837) + 10b
f1457837 _ZN2js9RunScriptEP9JSContextRNS_8RunStateE (416b7318, 416b6f10, fa9dbcd0, f1457b3c, e54bb000, fa9dbce0) + 2d7
f1457b3c _ZN2js23InternalCallOrConstructEP9JSContextRKN2JS8CallArgsENS_14MaybeConstructE (fa9dbd50, e4a24728, 416b6c68, f1457c03) + 263
f1457c03 _ZL12InternalCallP9JSContextRKN2js13AnyInvokeArgsE (e54bb000, e31eb038, ffffff82, f1457c7c, fa9dbe9c, 1) + 87
f1457c7c _ZN2js4CallEP9JSContextN2JS6HandleINS2_5ValueEEES5_RKNS_13AnyInvokeArgsENS2_13MutableHandleIS4_EE (8daff0e4, f1b24818, fa9dbe94, f13b4fb4, e54bb000, fa9dbeb8) + 46
f13b4fb4 _ZNK2js7Wrapper4callEP9JSContextN2JS6HandleIP8JSObjectEERKNS3_8CallArgsE (6, 416b6c68, 416b7258, f13a8784) + 200
f13a8784 _ZNK2js23CrossCompartmentWrapper4callEP9JSContextN2JS6HandleIP8JSObjectEERKNS3_8CallArgsE (f2232a40, 0, fa9dbf98, f13a6de3) + 104
f13a6de3 _ZN2js5Proxy4callEP9JSContextN2JS6HandleIP8JSObjectEERKNS3_8CallArgsE (e2d5b060, 1010000, 10000, f13a7809, e54bb000, fa9dbfe0) + eb
f13a7809 _ZN2js10proxy_CallEP9JSContextjPN2JS5ValueE (e7b08be0, ec112a00, 0, f14579ba) + 60
f14579ba _ZN2js23InternalCallOrConstructEP9JSContextRKN2JS8CallArgsENS_14MaybeConstructE (fa9dc22c, 3, fa9dc118, f1457c03) + e1
f1457c03 _ZL12InternalCallP9JSContextRKN2js13AnyInvokeArgsE (e2d5b060, 0, ffffff82, f1457c7c, f16b8000, fa9dc100) + 87
f1457c7c _ZN2js4CallEP9JSContextN2JS6HandleINS2_5ValueEEES5_RKNS_13AnyInvokeArgsENS2_13MutableHandleIS4_EE (e54bb000, 29, fa9dc248, f145c065, e54bb000, fa9dc2e8) + 46
f145c065 _ZN2js19SpreadCallOperationEP9JSContextN2JS6HandleIP8JSScriptEEPhNS3_INS2_5ValueEEES9_S9_S9_NS2_13MutableHandleIS8_EE (e54bb000, fa9dc270, 50a854c8, f1652875, e54bb000, fa9dc30c) + 427
f1652875 _ZN2js3jitL20DoSpreadCallFallbackEP9JSContextPNS0_13BaselineFrameEPNS0_15ICCall_FallbackEPN2JS5ValueENS7_13MutableHandleIS8_EE (2, ffffff81, e4a24f18, 2a7401e8, e54bb000, fa9dc3f8) + 237
2a7401e8 ???????? (2acd0acc, 4821, 6a5121a0, ffffff8c, 0, ffffff82)
50a854c8 ???????? (2444, e2d5f820, 2, d9d5d910, ffffff8c, 7b858bb0)
2a73f909 ???????? (2acd05c0, 3, fa9dc888, 0, e2d5f820, 0)
f162d642 _ZL13EnterBaselineP9JSContextRN2js3jit12EnterJitDataE (e54bb000, fa9dc588, fa9dc6f0, f1630993, e35cf448, f19105ac) + 15b
f1630993 _ZN2js3jit19EnterBaselineMethodEP9JSContextRNS_8RunStateE (e54bb000, fa9dc64c, fa9dc6f0, f1457837) + 10b
f1457837 _ZN2js9RunScriptEP9JSContextRNS_8RunStateE (e2f2d400, fa9dc6d0, fa9dc6e0, f1457b3c, e54bb000, fa9dc6f0) + 2d7
f1457b3c _ZN2js23InternalCallOrConstructEP9JSContextRKN2JS8CallArgsENS_14MaybeConstructE (fa9dc760, 7b8a36b0, fa9dc760, f1457c03) + 263
f1457c03 _ZL12InternalCallP9JSContextRKN2js13AnyInvokeArgsE (e54bb000, e31e9438, ffffff8c, f1457c7c, fa9dc8a4, e4a24de0) + 87
f1457c7c _ZN2js4CallEP9JSContextN2JS6HandleINS2_5ValueEEES5_RKNS_13AnyInvokeArgsENS2_13MutableHandleIS4_EE (e4a246c8, f1b24818, fa9dc8a4, f13b4fb4, e54bb000, fa9dc8c8) + 46
f13b4fb4 _ZNK2js7Wrapper4callEP9JSContextN2JS6HandleIP8JSObjectEERKNS3_8CallArgsE (461fe100, e20761c8, fa9dccc8, f13a8784) + 200
f13a8784 _ZNK2js23CrossCompartmentWrapper4callEP9JSContextN2JS6HandleIP8JSObjectEERKNS3_8CallArgsE (fa9dccf0, e54bb000, fa9dc990, f13a6de3) + 104
f13a6de3 _ZN2js5Proxy4callEP9JSContextN2JS6HandleIP8JSObjectEERKNS3_8CallArgsE (e2d5f820, e54bb000, fa9dcad8, f13a7809, e54bb000, fa9dc9f0) + eb
f13a7809 _ZN2js10proxy_CallEP9JSContextjPN2JS5ValueE (2, e54bb000, 0, f14579ba) + 60
f14579ba _ZN2js23InternalCallOrConstructEP9JSContextRKN2JS8CallArgsENS_14MaybeConstructE (fa9dce20, 7c32cd30, f1b24834, f1457c03) + e1
f1457c03 _ZL12InternalCallP9JSContextRKN2js13AnyInvokeArgsE (e54bb000) + 87
f1457c2d _ZN2js13CallFromStackEP9JSContextRKN2JS8CallArgsE (0, 0, 0, f1652df7) + 1b
f1652df7 _ZN2js3jitL14DoCallFallbackEP9JSContextPNS0_13BaselineFrameEPNS0_15ICCall_FallbackEjPN2JS5ValueENS7_13MutableHandleIS8_EE (fa9dcd48, f1b24820, fa9dd048, 2a74025f, e54bb000, fa9dcd48) + 4a7
2a74025f ???????? (2ac26a8e, 6821, 6a5121f0, ffffff8c, d9d36300, ffffff8c)
248a0b88 ???????? (2444, d9d3f100, 1, 0, ffffff82, 7b460ca0)
2a73f909 ???????? (2ac26150, 2, fa9dd1d8, 0, d9d3f100, 0)
f162d642 _ZL13EnterBaselineP9JSContextRN2js3jit12EnterJitDataE (e54bb000, fa9dced8, fa9dd040, f1630993, e2d10748, f19105ac) + 15b
f1630993 _ZN2js3jit19EnterBaselineMethodEP9JSContextRNS_8RunStateE (e54bb000, fa9dcf9c, fa9dd040, f1457837) + 10b
f1457837 _ZN2js9RunScriptEP9JSContextRNS_8RunStateE (d6836000, e54bb000, fa9dd030, f1457b3c, e54bb000, fa9dd040) + 2d7
f1457b3c _ZN2js23InternalCallOrConstructEP9JSContextRKN2JS8CallArgsENS_14MaybeConstructE (fa9dd1b8, f1495b92, fa9dd0b0, f1457c03) + 263
f1457c03 _ZL12InternalCallP9JSContextRKN2js13AnyInvokeArgsE (e54bb000, e2f2d438, ffffff82, f1457c7c, fa9dd1f4, e4a246a0) + 87
f1457c7c _ZN2js4CallEP9JSContextN2JS6HandleINS2_5ValueEEES5_RKNS_13AnyInvokeArgsENS2_13MutableHandleIS4_EE (e4a24560, f1b24818, fa9dd1f4, f13b4fb4, e54bb000, fa9dd218) + 46
f13b4fb4 _ZNK2js7Wrapper4callEP9JSContextN2JS6HandleIP8JSObjectEERKNS3_8CallArgsE (461fe100, e489ef38, fa9dd29c, f13a8784) + 200
f13a8784 _ZNK2js23CrossCompartmentWrapper4callEP9JSContextN2JS6HandleIP8JSObjectEERKNS3_8CallArgsE (f16b8000, fa9dd4e4, f1914040, f13a6de3) + 104
f13a6de3 _ZN2js5Proxy4callEP9JSContextN2JS6HandleIP8JSObjectEERKNS3_8CallArgsE (d9d3f100, e54bb000, fa9dd428, f13a7809, e54bb000, fa9dd340) + eb
f13a7809 _ZN2js10proxy_CallEP9JSContextjPN2JS5ValueE (1, e54bb000, 0, f14579ba) + 60
f14579ba _ZN2js23InternalCallOrConstructEP9JSContextRKN2JS8CallArgsENS_14MaybeConstructE (fa9dd900, d9d365f0, f1b24834, f1457c03) + e1
f1457c03 _ZL12InternalCallP9JSContextRKN2js13AnyInvokeArgsE (e54bb000) + 87
f1457c2d _ZN2js13CallFromStackEP9JSContextRKN2JS8CallArgsE (0, 0, 0, f1652df7) + 1b
f1652df7 _ZN2js3jitL14DoCallFallbackEP9JSContextPNS0_13BaselineFrameEPNS0_15ICCall_FallbackEjPN2JS5ValueENS7_13MutableHandleIS8_EE (e4a24450, ffffff8c, 2, 2a74025f, e54bb000, fa9dd728) + 4a7
2a74025f ???????? (2ac2ab3e, f821, 7b460cd0, ffffff8c, 0, ffffff82)
3c0c3208 ???????? (3045, d9d629a0, 3, d9d36520, ffffff8c, 52cd2140)
2a73f774 ???????? (3042, d9d629a0, 3, d9d36520, ffffff8c, 52cd2140)
2aad1e94 ???????? (2ae556d3, 6821, dd48e9d0, ffffff85, 76d68340, ffffff8c)
47f1f428 ???????? (3444, d9d62820, 3, d9d36520, ffffff8c, 52cd2140)
2a73f909 ???????? (2ae552e0, 4, fa9ddcd8, 0, d9d62820, 0)
f162d642 _ZL13EnterBaselineP9JSContextRN2js3jit12EnterJitDataE (e54bb000, fa9dd9b8, fa9ddb20, f1630993, f16b8000, fa9ddaac) + 15b
f1630993 _ZN2js3jit19EnterBaselineMethodEP9JSContextRNS_8RunStateE (e54bb000, fa9dda7c, fa9ddb20, f1457837) + 10b
f1457837 _ZN2js9RunScriptEP9JSContextRNS_8RunStateE (fa9ddbe0, d9b37ee0, f16b8000, f1457b3c, e54bb000, fa9ddb20) + 2d7
f1457b3c _ZN2js23InternalCallOrConstructEP9JSContextRKN2JS8CallArgsENS_14MaybeConstructE (e54bb4f0, e54bb000, fa9ddb90, f1457c03) + 263
f1457c03 _ZL12InternalCallP9JSContextRKN2js13AnyInvokeArgsE (fa9ddedc, fa9ddd1c, ffffff8c, f1457c7c, e54bb000, 52cd2140) + 87
f1457c7c _ZN2js4CallEP9JSContextN2JS6HandleINS2_5ValueEEES5_RKNS_13AnyInvokeArgsENS2_13MutableHandleIS4_EE (fa9ddcd8, fa9ddcd8, fa9ddc28, f1326a7c, e54bb000, fa9ddee8) + 46
f1326a7c _Z20JS_CallFunctionValueP9JSContextN2JS6HandleIP8JSObjectEENS2_INS1_5ValueEEERKNS1_16HandleValueArrayENS1_13MutableHandleIS6_EE (f16b8000, e5474150, fa9ddfd8, eed2a425, e54bb000, fa9dded0) + 217
eed2a425 _ZN19nsXPCWrappedJSClass10CallMethodEP14nsXPCWrappedJStPK19XPTMethodDescriptorP17nsXPTCMiniVariant (fa9de000, f16b8000, fa9de018, eed2aee3, e3943760, d6d8d0c0) + b93
eed2aee3 _ZN14nsXPCWrappedJS10CallMethodEtPK19XPTMethodDescriptorP17nsXPTCMiniVariant (fa9de0f0, 0, 2, ee52253e, d6d8d0c0, 3) + b3
ee52253e PrepareAndDispatch (45b42e00, fa9de140, 0, ee4ddfd5, d688f510, 45d2082c) + 126
ee4ddfd5 _ZN14nsObserverList15NotifyObserversEP11nsISupportsPKcPKDs (fa9de1a0, f16b8000, fa9de1c8, ee4de0ec) + 79
ee4de0ec _ZN17nsObserverService15NotifyObserversEP11nsISupportsPKcPKDs (616d692f, 2f736567, fa9de200, ee844efc, e7b079a0, 45d2082c) + ec
ee844efc _ZN7mozilla3net13nsHttpHandler15NotifyObserversEP14nsIHttpChannelPKc (45d20800, fa9de240, fa9de468, ee8c13b1, de96a000, 45d2082c) + aa
ee8c13b1 _ZN7mozilla3net13nsHttpChannel12BeginConnectEv (f16b8000, fa9de490, fa9de4b8, ee8c19f2, 45d20800, fa9de560) + b79
ee8c19f2 _ZN7mozilla3net13nsHttpChannel16OnProxyAvailableEP13nsICancelableP10nsIChannelP12nsIProxyInfo8nsresult (fa9de4e0, 0, fa9de588, ee5b6815, 45d20800, 80612338) + 14c
ee5b6815 _ZN7mozilla3net21nsAsyncResolveRequest10DoCallbackEv (80612330, fa9de5b0, fa9de5c8, ee5b6c24) + 2cd
ee5b6c24 _ZN7mozilla3net21nsAsyncResolveRequest15OnQueryCompleteE8nsresultRK9nsCStringS5_ (f1bac580, 1, fa9de5f8, ee5b45bd, 80612330, 80040111) + 48
ee5b45bd _ZN7mozilla3net15ExecuteCallback3RunEv (f1b6a2a0, 0, fa9de640, ee512380) + 25
ee512380 _ZN8nsThread16ProcessNextEventEbPb (f1b42400, e7b07830, fa9de6b8, ee53cb1c) + 292
ee53cb1c _Z19NS_ProcessNextEventP9nsIThreadb (f1b42400, fa9de6e0, fa9de718, ee92e6dd, f1b6a2a0, 0) + 35
ee92e6dd _ZN7mozilla3ipc11MessagePump3RunEPN4base11MessagePump8DelegateE (f16b8000, fa9de9e0, fa9de768, ee90b592) + 127
ee90b592 _ZN11MessageLoop11RunInternalEv (8, 0, fa9de780, ee90b891, f1b42400, ee90b888) + 1c
ee90b891 _ZN11MessageLoop3RunEv (fa9de7b0, fa9de7b0) + 27
f01ce720 _ZN14nsBaseAppShell3RunEv (f1b41400, 0, 0, f0962787) + 34
f0962787 _ZN12nsAppStartup3RunEv (e7b079a0, fa9de820, fa9de938, f09de60d, e46183a0, f1b17420) + 2d
f09de60d _ZN7XREMain11XRE_mainRunEv (fa9de960, f16b8000, fa9de998, f09de929, fa9de9e0, fa9de97b) + bc3
f09de929 _ZN7XREMain8XRE_mainEiPPcPK12nsXREAppData (fa9de9c0, f16b8000, fa9deb18, f09debdd, fa9de9e0, 6) + 1e7
f09debdd XRE_main (fa9defa4, 8057e44, 7, 805a075, 6, fa9df084) + 12f
0805a075 _ZL7do_mainiPPcS0_P7nsIFile (fa9df038, 805a185, 6, 805a19d, f1b6f060, 69671e92) + 377
0805a19d main (fa9df1b4, fa9df054, 8059921) + ba
08059886 _start (6, fa9df238, fa9df262, fa9df265, 0, 0) + 46